
 收藏本页
收藏本页

干货:数据挖掘方法论与工程化思考
2018年2月8日 浏览:103
数据挖掘的标准流程
CRISP-DM(cross-industry standard process for data mining), 即为”跨行业数据挖掘标准流程”。近年来CRISP-DM 在各种KDD过程模型中占据领先位置,2014年的统计数据表明其采用量达到43%。
通常来说,在各类KDD过程方法论中排在CRISP-DM后面的是SAS SEMMA。SEMMA代表建模的五个步骤,分别是samle,explore,modify,model和assess。SEMMA更偏重于数据挖掘的建模过程,与SAS的EM工具进行整合,其模型管理部署部分则体现在另外的工具套件中。
相比之下,CRISP-DM通用性更强,在大数据背景下的适应性也比较好。在此基础上我们制定了企业级的数据挖掘管理办法,源于CRISP-DM方法论并进行针对性细化,目的是对数据挖掘流程进行规范化管理。
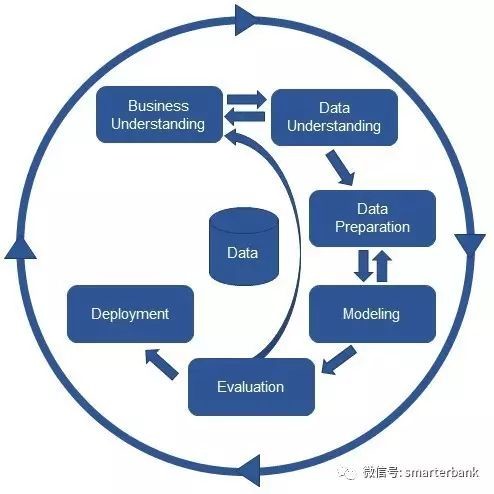
其实CRISP-DM和SEMMA并没有太多的分歧,具体选择哪项方法跟实际人员投入和工具基础有关。CRISP-DM反映了数据挖掘中的自然迭代规律,在实际工作中可以从其中某一点切入,整体呈现螺旋优化的过程,其对应的六个阶段分别如下:
1. 商业理解(business understanding),从商业的角度上面了解项目的要求和最终目的是什么. 并将这些目的与数据挖掘的定义以及结果结合起来。
2. 数据理解(data understanding),开始于数据的收集工作。接下来就是熟悉数据的工作;收集原始数据,对数据进行装载,描绘数据,并且探索数据特征,进行简单的特征统计,检验数据的质量。
3. 数据准备(data preparation),涵盖了从原始粗糙数据中构建最终数据集(将作为建模工具的分析对象)的全部工作。
4. 建模(modeling),各种各样的建模方法将被加以选择和使用,通过建造,评估模型将其参数将被校准为最为理想的值。
5. 评估(evaluation),在这一阶段中已经建立了一个或多个高质量的模型。但在进行最终的模型部署之前,更加彻底的评估模型。回顾在构建模型过程中所执行的每一个步骤,是非常重要的,这样可以确保这些模型是否达到了企业的目标。是否仍然有一些重要的企业问题还没有被充分地加以注意和考虑。在这一阶段结束之时,有关数据挖掘结果的使用应达成一致的决定。
6. 部署(deployment),即将其发现的结果以及过程组织成为可读文本形式.模型的创建并不是项目的最终目的。
数据挖掘的工程化基础
现阶段大数据、人工智能技术日新月异,对于数据科学领域的工作者来说,在学习新技术的同时更要积极探索适合企业发展的应用场景。尤其是在人工智能领域,现阶段业界对于技术和数据的讨论比较多,但在传统行业中的应用场景其实还差的很多。
当然这不是一蹴而就的,其实依赖于企业整体数据应用水平的提升。企业积极尝试应用新技术,在大数据分析挖掘领域进行试点,然后伴随数据挖掘从点到面的工程化铺开,人工智能的应用场景自然就会呈现出来。

通常传统企业在大数据挖掘领域会有所尝试,并在若干点上取得一定的进展,但距离整体铺开应该都还有很大的差距。企业数字化转型即业务从电子化到数字化的过程,对应着大数据应用深度和复杂度的持续提升,其中数据挖掘的工程化水平是一个重要的衡量标准。
数据挖掘在流程机制的建立过程中要充分实现工程化管理,同时注意加强知识技能的共享和传导。模型开发对应的是实验室机制,数据科学家发挥应有的核心作用。模型部署则是工厂化的概念,需要严格的验证测试过程,确保模型在生产环境稳定高效运行。模型运行结果在业务应用中发挥应有的数据价值,同时业务发展催生新的建模需求。模型管理在整体上发挥监督指导作用,负责数据挖掘全生命周期的管理。
数据挖掘开发部署的十步法
模型管理包括的内容很多,模型从开发到部署的过程中需要一套严格的操作办法,具体可分为十个步骤。这些步骤基本覆盖从模型开发到模型部署的全过程,同样适合于数据挖掘工作的监督管理或第三方评测。
十是一个有趣且比较完整的数字,当然内容可以细化或合并,将其增加或减少直至获得中意的数字。另外,模型都是有生命周期的,满足条件之后就要进行退役或下线,这个过程就不在十个步骤中体现了。
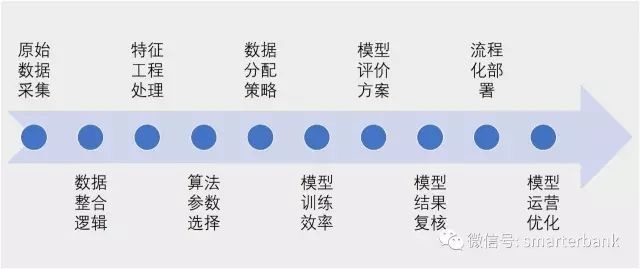
一、原始数据采集
检查原始数据提取过程(数据仓库、数据集市、外部数据等),注意查看是否按要求进行数据脱敏,以及是否进行数据质量检查。
1) 使用提供的数据提取方法,重新进行数据提取;
2) 抽样检查字段正确性和完整性;
3) 抽样查看字段中是否有敏感信息;
4) 统计数据总量及缺失量。
二、数据整合逻辑
检查数据处理及整合的基本思路,数据处理方法和流程(数据关联、链接)的正确性和完整性及处理结果的正确性。
1)检查数据预处理思路和处理方法是否正确;
2)检查数据处理流程(数据关联、链接)和整合过程是否正确且完整;
3)抽样检查数据处理结果,并与原数据进行对比,或设置检查点进行中间步骤的检查;
4)结合模型训练及预测结果,对数据处理逻辑进行完善。
三、特征工程处理
检查数据特征加工处理结果的正确性和稳定性。
1)检查特征提取方法是否正确且可以表达业务含义;
2)结合模型训练及测试结果,确认特征提取逻辑的完备性和稳定性。
四、算法参数选择
根据业务需求分析算法合理性,对比不同参数下的模型运行结果,确定算法及参数选择的合理性。
1)根据业务需求及数据特点选择合适算法,使用多种算法进行对比,得到适合建模场景的算法;
2)参数选择同理,对比多种参数选择结果,选最佳结果对应的参数。
五、数据分配策略
检查采用交叉验证方式建立模型过程中的数据集拆分策略及模型结果,对比不同分配策略下模型的效果。
1)检查数据集是否满足生产环境数据应用需求(如时序要求,数据量级限制等);
2)检查交叉验证过程中数据集训练和测试分配策略是否合理,包括拆分比例和方法;
3)对比多种分配策略,根据训练和预测结果选择恰当的分配比例,使得模型有良好的准确性、稳定性和泛化性。
六、模型训练效率
检查模型开发过程中所使用的工具情况,及模型开发过程的运行耗时。
1)检查模型开发平台或工具包在训练过程中的可靠性;
2)检查模型训练和测试耗时是否满足需求;
3)检查模型训练和测试的自动化支持能力。
七、模型评价方案
检查模型评价方案及评价指标的合理性。
1)使用多种评价指标分析模型训练效果,针对不同类型模型选择适当评价指标;
2)建议分类模型选择AUC、Precision、Recall和F1-score;回归模型选择Rmse、r2等;聚类模型选择聚合度等。
八、模型结果复核
检查模型评价结果的正确性,结果可再现及稳定性;
1)选择适当的评价指标,由评价指标结果判断模型结果优劣;
2)多次重复建模过程,改变模型开发输入数据,检查结果可再现性及稳定性。
九、流程化部署
检查模型部署在生产环境后模型运行过程的流程化能力,以及调度脚本的正确性和可维护性。
1)模型部署后,使用调度脚本控制数据挖掘模型实现流程化运行;
2)查看调度脚本的正确性和完整性,以及控制整个流程调整变化的能力。
十、模型运营优化
模型在日常运行过程中,检查批处理的输入数据采集、加工及运行过程的处理效率,检查模型输出结果的时效性和准确性。
1)确定数据处理用到的软硬件运行环境,分析其运算效率;
2)进行完整的数据批处理过程(数据采集、加工及预测)并记录耗时,检查是否有耗时较长的步骤,并寻求可改进的方法(编码改进,软件选择,设备更改);
3)检查模型运行结果是否满足前端业务应用需求,跟踪模型运行情况,定期进行模型结果分析,并适时启动模型优化更新。
Be the Change

与传统IT技能有所区别,在数据挖掘领域工作能够沉淀下来的并不完全是技术,更多的是对数据资产的理解与认知。如何最大化数据资产价值,如何通过数据产品完成价值传导,这些关键问题决定了创新是数据挖掘领域的核心能力。
技术日新月异,昨天的知识到了今天可能就是错误的,所以需要持续更新知识。想要通过数据挖掘提升企业竞争能力,那就先把自己武装起来,这样才有机会做些实事。
另外,数据挖掘的工作涉及人员、角色众多,需要与干系人建立良好的协会关系。单打独斗能做一两个模型,但是落地应用就需要多方参与,以共赢为基调才有可能推进模型在业务流程中的有效应用。共赢不难,只要清楚自己的定位和能力。
至于数据挖掘建模从点到面的推广,就需要建立完善的模型实验室和模型工厂运行机制,也就是要真正实现数据挖掘的工程化管理。这是目前传统企业进行数字化转型过程中需要重点考虑的问题,过程中涉及人员、工具、文化等影响因素。
—————————————————————————————————————
重要消息:本公众号已与国内多家投资机构达成合作,可为人工智能、大数据初创企业对接投资机构,您的企业如有投融资需求,请添加编辑微信:snogangel。

本公众号现面向人工智能和大数据爱好者征稿(无稿酬),如果您想让您的文章、观点分享给更多人工智能和大数据爱好者,请发邮件至351745027@qq.com。
欢迎扫码添加小编,加入人工智能和大数据公众号读者交流群,探讨、分享、交流!交流群每周会邀请行业专家进行在线分享!

 QQ二维码
QQ二维码 微信二维码
微信二维码